Kees Floor, Meteorologica, september 2002.
Al meer dan vijftig jaar werken meteorologen aan en met numerieke modellen van de atmosfeer (Spekat 2000). De producten van het ECMWF, dat in 2000 zijn 25 jarig bestaan vierde, zijn sinds 1981 op routinebasis in de weerkamers van de lidstaten beschikbaar. Je zou dan ook verwachten dat inmiddels de ‘ins en outs’ van atmosfeermodellen en van modeluitvoer bij geroutineerde meteorologen gemeen goed zijn, maar niets blijkt minder waar. Sommige zaken zijn nog niet bekend en vragen om nader onderzoek; voor andere geldt dat erover misvattingen rondzingen die een effectief gebruik van de modelproducten in de weg staan. Hieronder komen enkele van die misvattingen aan bod.
‘What you see is what you get’ De laatste verwachting is altijd de beste
Deze stelling berust op een misvatting. De clou zit hem natuurlijk
in het woord 'altijd'. Dat je nooit 'nooit' moet zeggen is algemeen
bekend, maar dat datzelfde ook geldt voor 'altijd', ontsnapt soms aan
de aandacht. Gemiddeld genomen is de laatste verwachting natuurlijk de beste,
maar niet altijd. De vorige versies van de User Guide (ECMWF 1995) melden
dat de kwaliteit van de meest recente prognoses voor dag 5 en 6 (de laatste
twee dagen van de ‘meerdaagse’ dus) in 20-25% van de gevallen achterblijft bij
die van de prognose van een dag eerder, zodat in die gevallen (je weet helaas
niet welke) beter de ‘oude’ prognose gebruikt hadden kunnen worden.
Doordat oude prognoses niet altijd onderdoen voor nieuwe, kunnen ze gezamenlijk,
- eventueel samen met de voorspellingen van nog een dag eerder, - worden gebruikt
als 'poor man's ensemble, bestaande uit twee of drie leden, waarvan het
gemiddelde beter scoort dan elk van de leden afzonderlijk.
Hoe hoger de resolutie, des te beter de prognose.
Op talrijke meteorologische centra waar atmosfeermodellen draaien,
is men bezig resoluties te verhogen en roosterpuntafstanden te verkleinen om
accuratere prognoses te krijgen. Leveren fijnmaziger modellen echter wel altijd
betere voorspellingen? Een hoge resolutie blijkt voor regionale modellen niet
alleenzaligmakend; gedetailleerd rekenen aan de fouten die door een te dichtbij
liggende rand het rekengebied binnendringen, levert geen extra winst. Mesinger
(2000) geeft voorbeelden waarbij een groter rekengebied even belangrijk is als
een hogere resolutie: de 29 km/50 lagen versie van een Amerikaans atmosfeermodel
leverde geen betere neerslagverwachtingen dan de even 'dure' 48 km/38 lagen
versie met een 2,5 maal zo groot rekengebied. COMET (2002b) toont een situatie
waarin een 80-km-roosterpuntmodel het beter deed dan een 22-km-model; oorzaak
was dat de zeewatertemperatuur, die in dit geval een belangrijke rol speelde,
beschikbaar was in een resolutie die beter overeenkwam met die van het grove
model dan met de resolutie van het fijnmazige model. Ook van HiRLAM zijn gevallen
bekend waarin een fijnere resolutie geen verbetering inhield; een voorbeeld
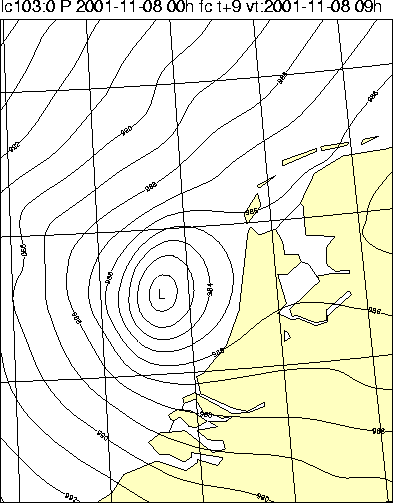
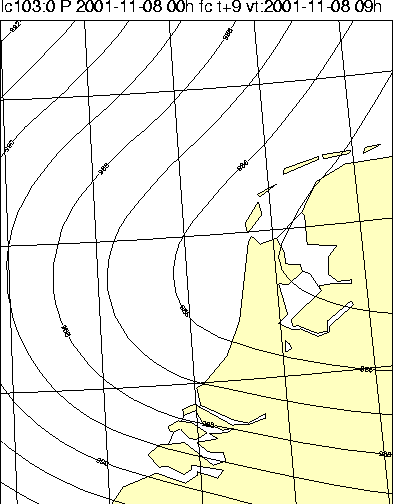
van zo'n situatie geeft figuur 1.
 |
 |
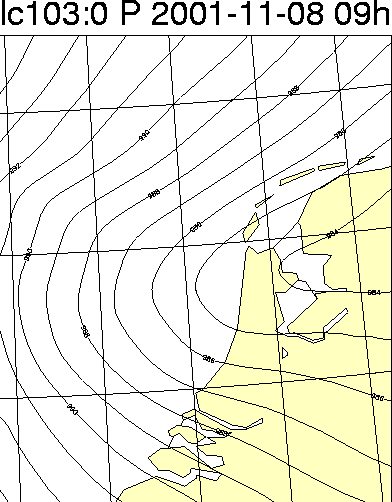 |
Figuur 1: HiRLAM +09-prognoses voor 8 november 2001 van twee modelversies met verschillende resolutie: 11 km (links) en 55 km (midden). Is de hoge resolutie een zegen voor de meteoroloog? In dit geval niet (zie de uiteindelijke analyse door het HiRLAM 11-km-resolutiemodel rechts), want het hogeresolutiemodel 'ontspoorde' in deze situatie duidelijk met een veel te sterke ontwikkeling van een polarlowachtig systeem, terwijl de grovere resolutie een beter resultaat liet zien.
Natuurlijk zijn er talrijke andere voorbeelden bekend die juist wel een toegevoegde
waarde van een hogere resolutie laten zien, maar in incidentele gevallen zet
het beter geachte model je op het verkeerde been. Dat is vooral het geval als
de data niet beschikbaar zijn in de voor dit type modellen benodigde resolutie;
de analysecyclus kan dan gaten opvullen met onjuiste details en vervolgens vanuit
een onjuiste beginpositie doorrekenen. Ook komt het modelleren van neerslagprocessen
en van processen in de grenslaag veel kritischer dan in grofmaziger modellen.
Kijken we op de wat langere termijn, dan geldt eveneens dat een hogere resolutie
niet langer borg staat voor een betere prognose. Zo levert het ensemblepredictiesysteem
(EPS) van het ECMWF naast de 'gewone' ECMWF-prognoses ook nog 51 prognoses van
een modelvariant met een lagere resolutie. Voor verwachtingen van 6 tot 10 dagen
vooruit heeft het uitkomen van de hogeresolutieverwachting echter geen grotere
waarschijnlijkheid meer dan de overige verwachtingen, gemaakt met een lagere
resolutie.
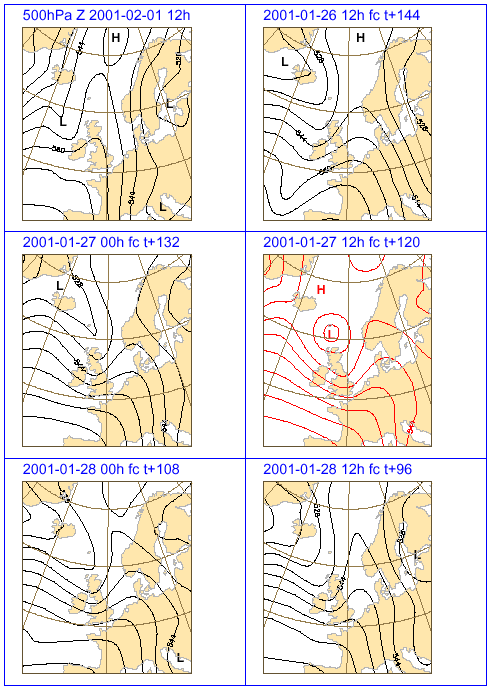
Consistente verwachtingen zijn beter dan inconsistente
Van tijd tot tijd lijken de atmosfeermodellen periodes door te maken
waarin significante verschillen optreden in opeenvolgende middellangetermijnverwachtingen,
- en soms zelfs in verwachtingen op de korte termijn, - geldig voor een zelfde
tijdstip. In de jaren tachtig van de vorige eeuw begonnen veel ‘meerdaagsemeteorologen’,
die geregeld met deze springerigheid van de modellen werden geconfronteerd,
de overeenkomst van dag op dag tussen prognoses voor een zelfde tijdstip te
gebruiken als maat voor de kwaliteit van de verwachting. (ECMWF 1995). Onderzoek
naar het verband tussen consistentie en kwaliteit leverden echter niets bruikbaars
op. Veranderingen in verwachtingen van dag op dag, zoals bijvoorbeeld in figuur
2, zijn onvermijdelijk en noodzakelijk (Persson 2002); je wilt namelijk dat
het verwachtingssysteem nieuwe waarnemingen volledig uitbuit om voorgaande analyses
van de toestand van de atmosfeer bij te schaven. Doordat de laatste verwachting
gebaseerd is op recentere waarnemingen, zal ze door de bank genomen beter zijn
(echter niet altijd: zie boven onder het kopje: 'De laatste verwachting is
altijd de beste'). Meestal zijn de veranderingen in opeenvolgende verwachtingen
gering, zeker voor de eerste vijf of zes dagen, maar af en toe treden toch grote
verschillen op. Dat laatste is bijvoorbeeld het geval als er nieuwe waarnemingen
beschikbaar komen uit gebieden waar de gevoeligheid van het model groot is.
Het schrijnende van de situatie is dat het model dus af en toe inconsistent
ofwel springerig moét zijn om de nieuw binnengekomen waarnemingen ten
volle te kunnen benutten, terwijl de meteoroloog juist wél consistent
moet zijn om het publiek niet in verwarring te brengen! En dat terwijl diezelfde
meteoroloog niet kan bepalen welke verwachting de beste is, zo er al een de
beste is. Er is namelijk geen significant verschil in kwaliteit tussen consistente
en inconsistente verwachtingen.
|
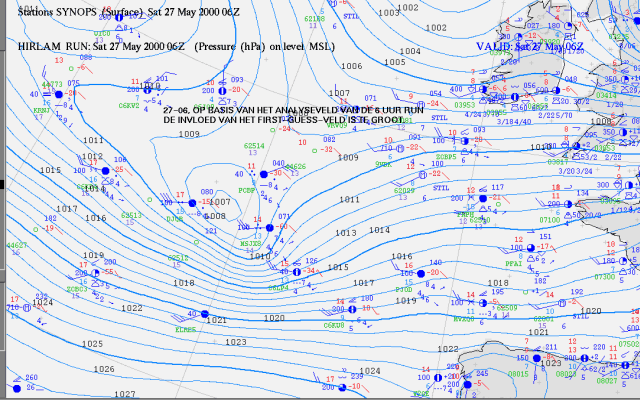 Figuur 3: HiRLAM-analyse van 27 mei 2000 06 UT met waarnemingen. De luchtdruk in de kern van de depressie is ongeveer 5 hPa te hoog; het lagedrukcentrum ligt in de modelanalyse te veel naar het westen. Deugt het model niet in dit geval? |
 |
Soms zijn de modellen inconsistent, zijn ze het oneens
of spreken ze elkaar tegen
Moeten we nu stellen dat inconsistentie wordt veroorzaakt door het
assimileren van nieuwe waarnemingen. COMET (2002a) en Kok (2002) formuleren
het liever anders: inconsistentie is onlosmakelijk verbonden met de beperkingen
aan de voorspelbaarheid. Als alle verwachtingen maar vallen binnen de range
die het ensemblepredictiesysteem (EPS) bestrijkt, is er eigenlijk niets aan
de hand. Hoe groter de spreiding in het ensemble of hoe moeilijker voorspelbaar
de situatie, des te groter de kans op 'rare sprongen'. Deze springerigheid neemt
nog verder toe bij het vaker draaien van een weermodel, bijvoorbeeld om de 6
uur in plaats van om de 24 uur (Kok 2002).
Als we ons in deze redenering kunnen vinden, dan komt het ook niet meer voor
dat modellen inconsistent zijn, van elkaar afwijken of elkaar tegenspreken.
Inconsistent impliceert als norm 'consistentie' en deze norm accepteren
we dus niet langer. Managers zouden spreken over de noodzaak van een 'paradigmashift'
onder de meteorologen. Het oude, deterministische, paradigma, - nog steeds de
actuele 'mindset' van veel meteorologen, - schrijft voor dat opeenvolgende
modelruns de weersituatie van een bepaald moment steeds goed of op z'n minst
steeds beter moeten voorspellen; inconsistentie bestaat in deze visie écht
en is uit den boze. Het nieuwe, probabilistische, paradigma ziet elke verwachting,
al dan niet afkomstig van hét operationele model, als een nieuwe greep
uit de vele mogelijkheden binnen de ruimte die het ensemble toelaat of die de
mate van onvoorspelbaarheid van dat moment met zich meebrengt; inconsistentie
is inexistent. Verschillende weermodellen kunnen het niet langer met elkaar
oneens zijn en elkaar niet meer tegenspreken; ze hebben alleen nog een andere
greep gedaan uit de scenario's die het ensemble aanreikt. De paradigmashift
houdt in het afzweren van het deterministische paradigma en het daarvoor in
de plaats omarmen van het probabilistische.
Met een 11 km rooster kun je weersystemen vanaf 22
km goed beschrijven.
Weer een stelling over resolutie en roosterpuntafstanden en ook deze blijkt
niet waar. Mogelijk is een verschijnsel dat slechts twee of drie roosterpunten
omvat, terug te vinden in de analyse, maar van enige nauwkeurigheid is dan beslist
geen sprake. Bovendien wil je niet alleen dat het verschijnsel in de analyse
tot zijn recht komt, maar ook in de daaropvolgende prognoses. Het weersysteem
mag niet door rekentechnische oorzaken degenereren in de loop van het rekenproces.
Om degeneratie te voorkomen, zijn 2 of 3 roosterpunten niet genoeg; eerder zijn
8 tot 10 roosterpunten nodig (COMET 2002b). Je mag van fijnmazige modellen wel
verwachten dat ze een signaal afgeven voor het optreden van bijvoorbeeld zeewind
of het passeren van een kleinschalig gebied met zware neerslag, maar op de getoonde
details mag je niet blindvaren.
 Figuur 5: Buiencluster op 30 km rooster. Het model mist veel informatie. |
|
Waarnemingen moeten naadloos passen in de modelanalyse
'In het huidige sterk door computermodellen, progtemps en automatische
waarnemingen bepaalde wereldje is één van de basisprincipes om
betrouwbare verwachtingen te maken nog altijd vergelijking van de modeldata
met de werkelijkheid', zo las ik onlangs in een email van een meteoroloog.
'Om een zo goed verwachting te krijgen, moet de analyse exact overeenkomen
met de waarnemingen; is dat bij een bepaalde modelrun onverhoopt niet het geval,'
(zoals bijvoorbeeld in figuur 3), 'dan wantrouwen we alle prognoses',
zo wordt vaak gedacht. Ten onrechte, want een modelanalyse is namelijk niet
alleen gebaseerd op waarnemingen, maar ook op een zogeheten gisveld. Het gisveld
is de prognose van de vorige modelrun die geldig is voor het nieuwe analysetijdstip.
Zo'n gisveld bevat dus veel informatie uit het verleden over de toestand van
de atmosfeer; deze informatie wordt zo goed mogelijk benut voor het analyseren
van de weersituatie op het tijdstip van de waarnemingen. Bij de analyse wordt
het gisveld wel in de richting van de waarnemingen getrokken, maar vrijwel nooit
voor de volle 100%.
Er is nog meer te zeggen over verschillen tussen analyse en waarneming. Het
kan bijvoorbeeld zijn dat de modellen niet over dezelfde meetgegevens beschikken
als de meteoroloog die de modelanalyse op waarde moet schatten. Zo genereren
de Zeeuwse windmeetpalen geen SYNOP's en komen de gegevens daardoor niet in
het buitenland terecht. De wind in de Zeeuwse kustwateren in een analyse van
het Britse MetOffice kan dus gemakkelijk afwijken van de metingen die in Nederland
opvraagbaar zijn. Maar ook als het model waarnemingen wél heeft gebruikt
voor de analyse, zijn verschillen mogelijk. Dat heeft uiteenlopende oorzaken,
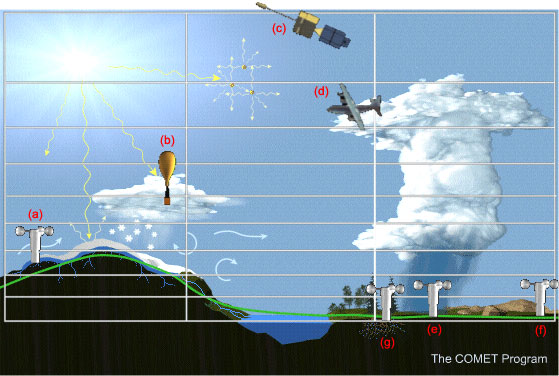
waarvan sommige geïllustreerd kunnen worden met behulp van figuur 4 (COMET
2002b).
Het roosterpuntmodel dat in die figuur is geschetst, gebruikt SYNOP's (a, e,
f,g), een TEMP (b), satellietdata (c), en vliegtuigwaarnemingen (d) om per vakje
'het weer' te bepalen. In sommige vakjes is echter geen enkele waarneming beschikbaar;
daar moet het model dus wel terugvallen op het gisveld.
Het oplossend vermogen van die waarnemingen wijkt vaak af van de modelresolutie.
De figuur bevat verscheidene voorbeelden. (1): De SYNOP-waarneming (a) rapporteert
uit een vakje met grote verschillen in sneeuwbedekking, topografie en temperatuur.
(2) De radiosonde (b) die een sneeuwbui doorkruist en het vliegtuigtuig dat
door het aambeeld van een onweersbui vliegt, genereren meetwaarden die kleinschaliger
zijn dan het model 'aankan'. (3): De weersatelliet (c) registreert stralingsgegevens
die betrekking hebben of verscheidene, boven elkaar gelegen vakjes; nu is de
resolutie van de waarnemingen dus juist grover dan die van het model. (4) In
het vakje rechtsonder beschikken we over drie SYNOP-waarnemingen: een voor de
bui uit, een in de bui en een erachter; de modelanalyse kent per vakje maar
één mogelijkheid.
In het geval van de SYNOP's (b, c en d) gaat het ook nog om tegenstrijdige waarnemingen
uit één vakje; het kan zijn dat het analysesysteem ze daarom verwerpt.
Onmiskenbaar foute waarnemingen zijn gemakkelijk op te sporen en te verwerpen,
maar voor kleinere fouten of kleinere afwijkingen van het gisveld is dat veel
moeilijker. Bovendien hebben we te maken met marges in de meetwaarden, die per
meetsysteem anders zijn.
In een model moeten de samenhangen tussen verschillende grootheden kloppen.
In het geval van de radiosondewaarneming die de sneeuwbui doorkruist, zal het
model vocht toevoegen om de modelsituatie dichter bij de gemeten werkelijkheid
te brengen. Een ander voorbeeld: als een lagedrukgebied aan de grond niet is
terug te vinden in de bovenlucht, zal een model de depressie afvlakken, omdat
haar aanwezigheid niet wordt ondersteund door de bovenluchtwaarnemingen.
Door alle genoemde, op zich goed te begrijpen, oorzaken kunnen er dus verschillen
optreden tussen analyse en waarneming. Natuurlijk komt het voor dat waarnemingen
ten onrechte verworpen worden en dat belangrijk weer daardoor wordt gemist,
maar toch hoeven verschillen tussen waarnemingen en modelanalyse niet in te
houden dat de modelprognoses niet kunnen deugen.
Conclusie
Consistente verwachtingen hoeven niet beter te zijn dan inconsistente. De verwachting
van gisteren kan beter zijn dan die van vandaag. Hogere resolutiemodellen zetten
je soms op het verkeerde been. Er zijn veel meer dan twee roosterpunten nodig
om een weersysteem te kunnen beschrijven én vast te houden in de prognoses.
Analyses hoeven niet alle geschikte waarnemingen voor de volle 100% te honoreren.
Op het gebied van voorspelbaarheid zitten veel meteorologen nog vast aan hun
oude 'mindset'; ze zijn nog niet klaar voor de 'paradigmashift'
. En de slogan 'what you see is what you get' biedt geen houvast voor
het beoordelen van modeluitvoer. Deze conclusies doen ons soms wel even slikken,
maar dienen toch onder ogen gezien te worden.
Literatuur
COMET (2002a), Interpretation of Global Model Forecast "Flipflops"; www.meted.ucar.edu/nwp/pcu3/cases/ens08apr02/menu.htm
COMET (2002b), Ten Common NWP Misconceptions, Computer-based Training Webcast; www.comet.ucar.edu/modules/ten.htm
ECMWF (1995), User Guide to ECMWF products v2.1, Meteorological Bulletin M3.2, Reading UK, ECMWF december 1995
Floor (2002), Management jargon; www.floor.nl/management/paradigma.html
Kok, K (2002), Springerigheid van modellen, KNMI memorandum (in voorbereiding).
Mesinger (2000), Limited Area Modelling: Beginnings, state of the art, outlook, in: Spekat, A. (2000), 50 years Numerical Weather Prediction,Berlin, EMS
Persson, A. (2002), User Guide to ECMWF forecast products v3.2, Meteorological Bulletin M3.2, Reading UK, ECMWF maart 2002; www.ecmwf.int/products/forecasts.
Spekat, A. (2000), 50 years Numerical Weather Prediction, Berlin, EMS